redis lua脚本的妙用
在本人的毕业设计——用户标签系统里,有个给管理平台(也就是前端模块)提供的功能:统计storm在执行某个”批量处理“任务的进度。该任务的示意图如下:原始数据(OriginData)从MySQL抽取出来,通过storm工程A、B的处理,转为最终数据(Label)落到ES中。整个流程类似于ETL吧~

整个流程涉及的组件很多,现成的”进度统计“接口就别想了,只能自己开发。分布式系统下,实时高效的存取少量数据(也就是进度数据),第一时间想到的就是使用Redis。于是吭哧吭哧搞起来(注意看红字):
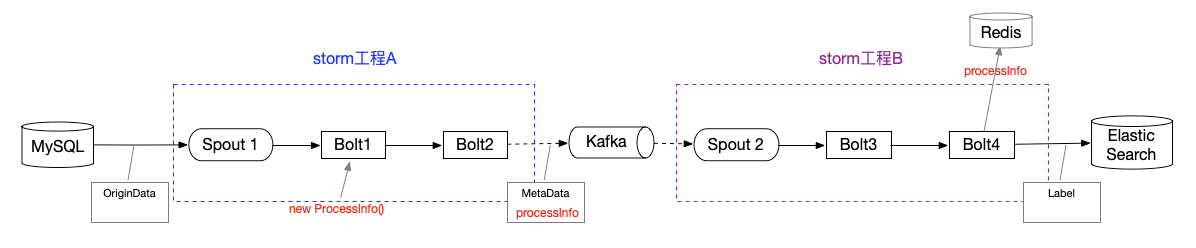
实现方式大概是:上游用一个对象ProcessInfo,用于标记进度信息,并封装进待处理的数据中,随着数据传入kafka,再传到下游;当执行到最后一个bolt后,将processInfo序列化到Redis里,供前端模块实时读取。
ProcessInfo对象如下所示:
1 | public class ProcessInfo implements Serializable { |
问题来了,Kafka开了多个partition,消息只设置了局部有序规则(同一个userId的消息有序),但不能保证processInfo严格有序。其实给前端看的东西嘛,也没必要太严谨。一开始我把storm spout的Thread.sleep(time)的参数给的很大,这时并发程度很低,没有任何问题。
但是当我取消sleep time后,并发上来了,问题也随之来了!
如图,可能100/100在80/100之前先传到redis,这样一来,最终进度就是80/100无法到达终点了!
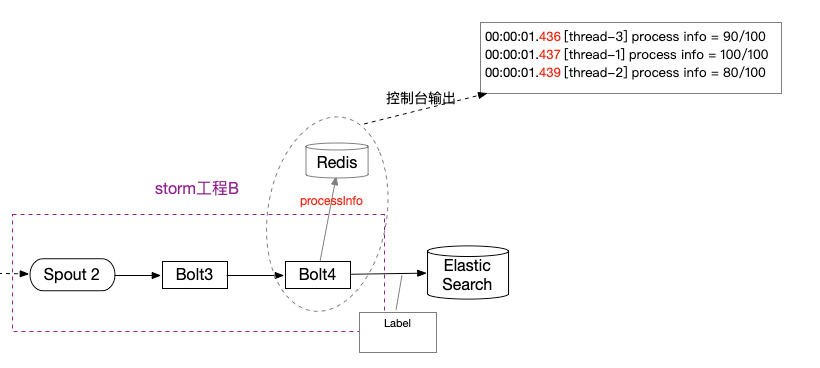
一开始想到的解决方法是:如果到达终点,就设置#END标识,其他后续请求发现值为#END,就不进行redis set操作了。这样一来,上述场景中80/100就无法在redis中成功set。可是每次请求都需要加个redis get判断操作,开销翻倍了,而且这样操作不具备原子性。
灵机一动,我想到之前redis分布式锁用到lua脚本,是不是可以把get和set的逻辑整合到脚本里。于是我就依葫芦画瓢写了一段,结果真的跑成了!
1 | if redis.call('get', KEYS[1]) ~= '#END' |
此外,lua脚本还具有原子性,并发问题也顺带解决了